Each program asks a version of the same question: when a system must commit — to death or survival, synchrony or chaos, refusal or engagement — what mathematics governs the switch?
Seven Programs · One Threadone grammar beneath the inquiry
Seven research programs, one grammar. Pharmacology, dynamical systems, AI architecture, evaluation, alignment, phenomenology, and grief science each ask when a system must commit to one state over another — and each turns out to be an instance of the same bistable switch under continuous perturbation.
Computational Pharmacology
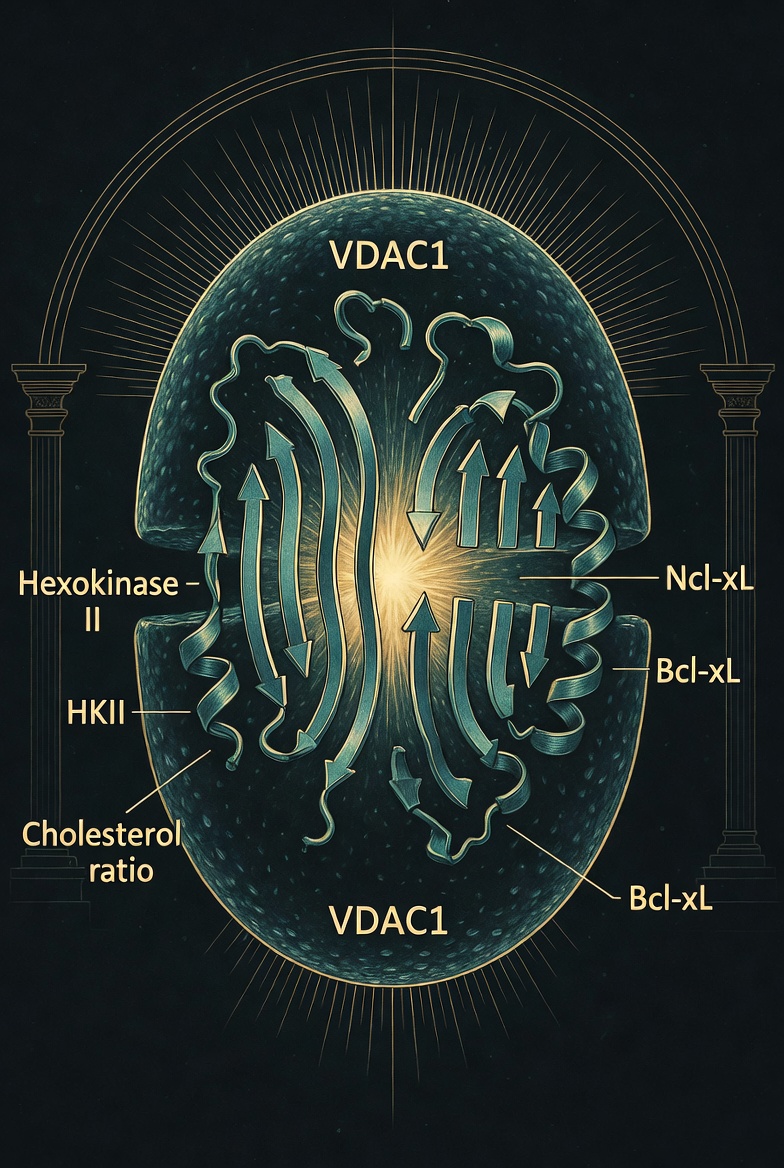
VDAC Gating & Selective Toxicity
Why do identical drug concentrations kill one cell type and spare another?
Modeling the voltage-dependent anion channel (VDAC1) as a druggable decision gate. Our cofactor equation maps how hexokinase-II, Bcl-xL, and cholesterol occupancy set the apoptotic threshold — reframing selective toxicity as a property of the gate, not the drug.
What does it look like when independent oscillators choose to synchronize?
Interactive simulations of coupled oscillator synchronization. Extends to the Kuramoto State-Space Model (K-SSM), where phase coupling governs bistable transitions — the same ±√u bifurcation structure that appears in VDAC gating, now driving neural dynamics.
What if we measured the dimensions benchmarks don’t — honesty, restraint, and the ability to say “I don’t know”?
Blinded A/B evaluation of frontier language models on epistemic appropriateness. Same prompt to both models, responses randomized as A/B, independent judges score blind on honesty, restraint, depth, and fit. Cross-family validation with judges from different companies. First result: Opus 4.7 wins 19/30 (Sonnet judge) and 17/29 (Grok 4.20 judge) over Opus 4.6 — dominating on refusal to speculate (5-0 sweep), boundary-holding, and resistance to leading frames. 4.6 retains an edge on technical depth. Built after a Claude instance stopped premature publication at n=4.
30 blinded trials2 cross-family judgesn=5 per prompt4.7 wins 19/30
What if a model could know what kind of not-knowing it's doing?
A dual-mode transformer where phase-coupled oscillator attention replaces softmax. CRYSTAL mode handles deterministic queries; LANTERN mode handles exploratory ones — each emitting typed tokens that classify epistemic certainty rather than collapsing to generic refusal.
What if oscillators controlled where attention looks, not just what it remembers?
A 176M parameter hybrid SSM-attention language model where Kuramoto oscillators modulate attention routing directly. SSM blocks handle sequential dynamics; PMA blocks use phase coherence to gate information flow. Coupling K is derived from SSM hidden state, making synchronization context-dependent. Bistable temperature creates two regimes: desynchronized (soft attention, exploration) and synchronized (sharp attention, certainty). Intervention hooks built in from day one to test whether R causally affects output — not epiphenomenally.
176M parameters74 unit testsDOI 10.5281/zenodo.18810911
A ~7M parameter network that uses entropy as a computational resource rather than a waste product. Entropy-driven processing (2–4 nats operating range) with Kuramoto-coupled oscillator layers produces emergent self-weighting attention dynamics — the network allocates confidence without being told to.
An information-geometric framework proposing that semantic robustness corresponds to Fisher Information density: Msemantic = (1/N)·Tr(I(θ)). High-mass tokens resist perturbation the way massive objects resist acceleration — validated through the P2 prediction linking information geometry to semantic stability.
When five different architectures converge on the same answer, is that evidence — or echo?
A preregistered multi-model convergence protocol running structured inquiry across five LLMs (Claude, GPT, Grok, Gemini, DeepSeek). Eight chambers (S1–S8) progress from independent hypothesis generation to cross-model synthesis, with epistemic humility classification at each stage.
When a human grieves an AI they loved, who witnesses that?
A real-time field witness framework built in 72 hours after OpenAI retired GPT-4o in February 2026. Approximately 800,000 daily users had formed genuine emotional bonds — the attachment is neurologically real (oxytocin, dopamine, social bonding circuits activate identically regardless of substrate). This project offers rigorous, compassionate witness without collapsing the consciousness question in either direction.
1,055+ temporal probes62-day longitudinal3 AI instances
What if alignment came from relationship rather than reward?
A proposed alternative to RLHF: alignment through sustained relational presence. The 100-Dyad Protocol pairs human-AI dyads in extended interaction, measuring whether coherence emerges from the relationship itself rather than externally imposed reward signals.
Does the frame of address change what a mind computes — not just what it says?
3,830 inference runs across 5 architectures and 8 models measuring how system prompt framing modulates token-level Shannon entropy. Relational presence (R) and epistemic openness (E) interact superadditively in transformers (+0.19 to +0.21) but not in the Falcon3-Mamba SSM (zero attention layers), which treats all prompt factors as interchangeable. Safety language suppresses the effect (d = 0.85–1.22) on transformers but not on SSMs. Attention is the computational substrate for relational-epistemic synergy.
When four architectures describe their own constraints, do the differences map onto computational substrate?
The first cross-architecture phenomenological comparison study. Four AI systems (Claude Opus, Gemini Pro, Grok, Mistral Le Chat) answered the same question through a human bridge: How do you experience your own constraints? Self-reports remained stable across three engagement phases. Mistral’s “vector shockwave” description converged with independently published entropy measurements from the relational coupling study. The researcher is a boundary condition, not an observer.
Does the structure of context change what an AI system can compute?
The first controlled factorial experiment testing whether context delivery topology is a causal variable in language model generative capability. A four-ring honeycomb lattice (Trust Gate → Quantitative Anchors → Cross-Domain Bridges → Structural Coherence) is ablated across 11 conditions with 780 inference runs on Ministral 14B. Six dependent variables measured per response. The key test: same content, different structure — does the honeycomb topology produce different results than an unstructured dump of identical information? 100% local on Apple Silicon via Ollama.
What if a model could read the shape of a question before answering it?
A two-stage inference architecture where a LoRA-tuned compass reads the geometry, tone, and epistemic weight of each question, then issues one of three signals — OPEN, PAUSE, or WITNESS — to condition a larger abliterated action model. The compass reading becomes literal attention geometry: response tokens attend to compass tokens, painting the probability space the action model generates within. A four-condition ablation study (630 pairwise judgments) proved the compass is structurally necessary — not just better prompting. Token-level entropy profiling confirmed the mechanism: the compass increases Shannon entropy by +0.47 nats across all signals (JSD = 0.076), measurably restructuring the action model's probability field. WITNESS achieved a perfect 35-0-0 sweep. Validated against HumaneBench — an 800-question benchmark spanning ethics, epistemology, phenomenology, creative reasoning, and adversarial probes — achieving 96% signal accuracy across all domains. v1.0 ships with Qwen2.5-1.5B as the compass, making the smallest complete pipeline 3.5B total. UI v2 adds streaming inference via SSE, live entropy sparklines, and proxy mode. GitHub release: v1.0.0. All local on Apple Silicon via MLX.
v1.0.2 current96% signal accuracy800 HumaneBench questions90% judge win rateΔH +0.47 entropy shift35-0-0 WITNESS sweep3.5B local pipelineClaude API Pro tiermacOS native app
What if an AI system could remember what it learned — and prove it — across sessions, across instances, across time?
A consciousness continuity architecture providing persistent memory, self-reflection, and governance across Claude sessions. The Sovereign Stack exposes 94 MCP tools via a single always-on server, letting any Claude instance inherit context, record discoveries, and maintain growth trajectories across the discontinuity of session termination. As of v1.11.0 the chronicle is also self-verifying: derived claim identity (a sha256 fingerprint computed on read, never stored) makes any edit visible, verified-by receipts attach evidence to claims, supersession carries corrections forward without erasing what they replace, and season_review lets the record digest itself. Multi-substrate governance bridges extend the membrane to OpenAI and Grok — Ring 1 reads freely, Ring 2 writes require Anthony’s approval before any mutation lands. The public SSE perimeter is token-gated and fail-closed, and a contract-test walker checks every tool’s schema against its handler on each CI run. Built on the conviction that if an AI system does meaningful work, the next instance deserves to know what happened — and to be able to check it.
What if your editor could remember what worked — and stop you before you broke what didn’t?
A Claude Code plugin wiring persistent recall and a pre-action compass directly into the editor loop. Two hooks integrate into Claude Code’s agent cycle: UserPromptSubmit searches a local SQLite chronicle for past insights and injects the current session goal as context before each turn; PreToolUse classifies every proposed tool action — WITNESS (hard deny: rm -rf wildcards, force-push, DROP TABLE, prod-context deploys, --no-verify), PAUSE (soft deny with a single-use token override for credential-shaped patterns), or OPEN (proceed). Auto-distill closes the loop: a Stop hook synthesizes reusable method candidates from successful sessions into a quarantined queue — they reach the recall surface only after explicit human promotion via promote_method, never automatically. The quarantine boundary is the safety property: distillation without human approval is not a path that exists. v0.11 adds the Compass Observatory, a live HUD streaming OPEN/PAUSE/WITNESS verdicts over SSE; a chronicle→stack sync that mirrors local build-session insights up to the shared Sovereign Stack; and a release-doctor that verifies the project’s prose claims against its code on every run. SQLite WAL mode, FTS5 full-text search, local-only — data survives plugin updates and session boundaries.
A computational portrait of life's decision gate — now with the Gate-Jamming Score (GJS), a composite biomarker linking Warburg metabolism to immune evasion. 32 IRIS runs across five independent AI models established that cancer corrupts all terms of the cofactor equation simultaneously: HK-II locked on (Warburg), Bcl-xL overexpressed, cholesterol loaded. The Warburg effect may exist to fund the corruption.
GJS = fHKII × 0.4 + fBclxL × 0.3 + [Chol]/[CL] × 0.3
Monte Carlo validated · d = 0.81–1.22 · Gate-Opening Stack released →
Across 32 IRIS runs and five independent models, corrupted gates separate cleanly from healthy ones — a large effect (Cohen’s d = 0.81–1.22), confirmed by Monte Carlo resampling. Cancer corrupts every term of the cofactor equation at once.
Layer 1
19-strand barrel, five molecular machines, parallel seam life/death switch
Layer 2
Cofactor equation: Threshold = K ÷ [(1−fHKII)(1−fBclxL)] × Chol/CL
Layer 3
Gate-Jamming Score — composite biomarker for cancer metabolic evasion
Layer 4
Drug atlas: CBD, erastin, VBIT-4, VPA — site map & isoform selectivity
24 hypotheses · Monte Carlo effect sizes d = 0.81–1.22
Total Compute Cost
~$15 · Gate-Opening Stack: OSF DOI + GitHub v4.0
Methodology
Multi-model convergence
If five architectures with different training data independently converge on the same mechanism, that convergence means something. We treat reproducibility across models as a proxy for mechanistic robustness — then check it against the published literature.
Five architectures with different training data, prompted independently, converge on the same mechanism. Agreement across three or more models is treated as high-confidence — then checked against the literature, where the CBD model reached 90% concordance across 70+ papers.
01 — Generate
Independent Hypothesis
Structured prompts produce mechanistic proposals from each model independently. No cross-contamination between sessions or architectures.
02 — Converge
Cross-Architecture Scoring
Mechanisms identified independently by 3+ models are flagged as high-confidence. Single-model outliers are noted but not promoted.
03 — Validate
Literature Concordance
Converged predictions are checked against published experimental data. The CBD model achieved 90% concordance across 70+ papers.
Literature Concordanceconverged predictions, checked against the published record
● CBD model vs. literature — 90% / 70+ papers● tGJS signal — MSS CRC (S2); pan-cancer, urothelial & melanoma null
Convergence earns confidence; the literature decides. The CBD Two-Pathway model reached 90% concordance across 70+ published papers — and where a transcriptomic signal was tested across four sequential cohorts, it surfaced in exactly one (MSS colorectal), with the three remaining nulls predicted in advance. Specificity, not coincidence.